Auto Insurance Fraud Detection with Machine Learning
A practical actuarial data science project applying supervised machine learning models such as Logistic Regression, Random Forest, and Gradient Boosting, to automatically detect fraudulent auto insurance claims, with SMOTE used to address class imbalance.
Ebenezer Afonja
This project explores three of the most widely used machine learning algorithms in actuarial analysis: Logistic Regression, Random Forest, and Gradient Boosting, applied to a real auto insurance dataset to detect fraudulent claims. Logistic Regression serves as the interpretable baseline that has long been the actuarial standard, Random Forest brings the power of ensemble decision trees to capture non-linear patterns and Gradient Boosting represents the modern state-of-the-art for structured tabular data. By training all three on the same SMOTE-balanced training set and evaluating them on identical test data, the project produces a clean comparison based on ROC-AUC, Precision, Recall, and F1-Score exploring which algorithm performs best when fraud detection is the goal.
The full repository, including the dataset and Jupyter notebook, is available on GitHub.
Objectives
- Build a binary classification pipeline to detect fraudulent insurance claims from historical data.
- Address the inherent class imbalance in fraud datasets without compromising model integrity.
- Compare three machine learning models and identify the most effective approach for actuarial fraud detection.
- Extract interpretable insights about the key drivers of fraud through feature importance analysis.
Understanding the Data
The first step in any ML project is understanding what you’re working with. The dataset contains roughly 1,000 auto insurance claims with 40 features per claim it includes demographics, incident details, vehicle information, and claim amounts plus a target column indicating whether each claim was fraudulent.
The Class Imbalance Problem
Before training any model, checking class balance is critical. Approximately 25% of claims in the dataset were fraudulent meaning a naive model that simply predicts “not fraud” for every claim could achieve 75% accuracy while catching zero fraudsters. This is the central challenge of fraud detection.
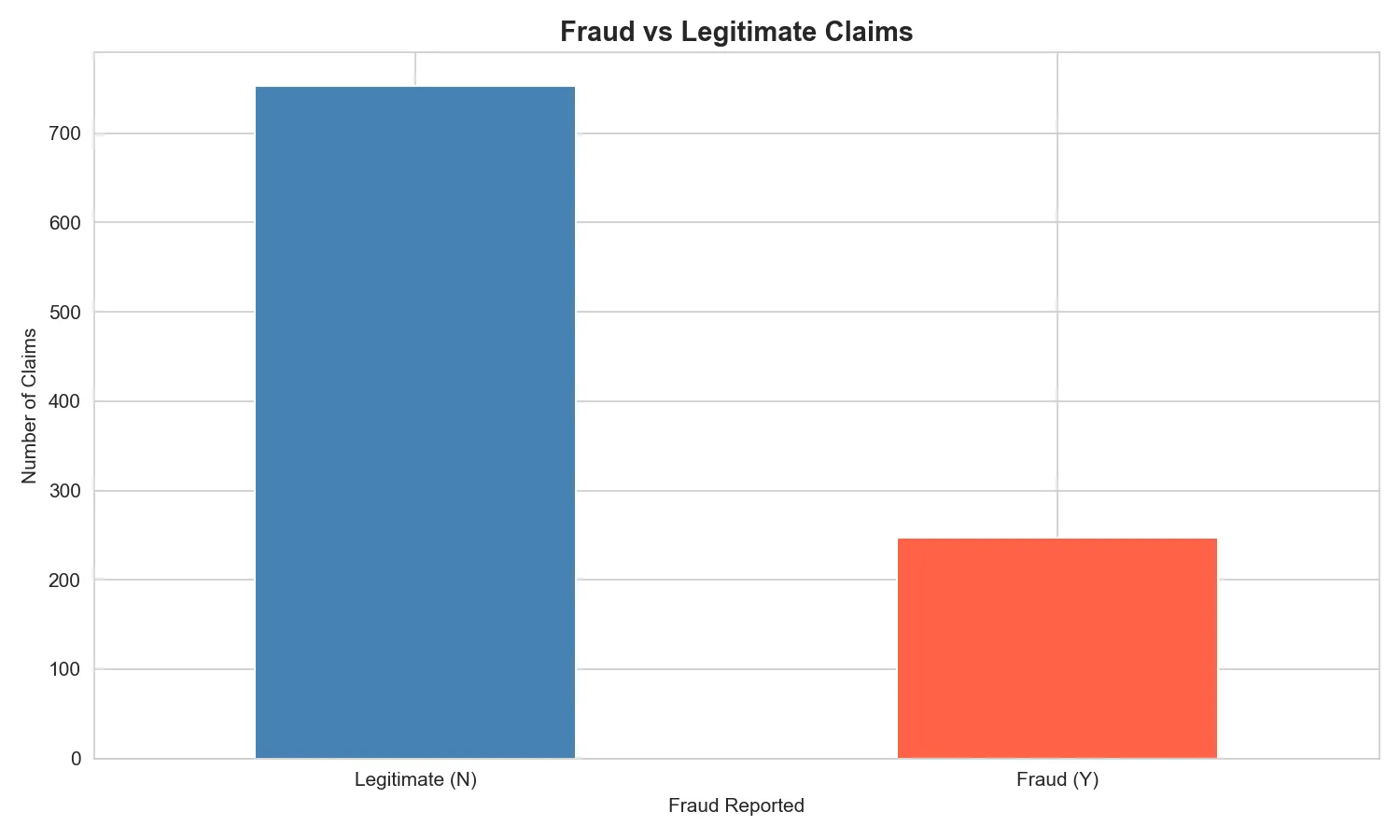
This imbalance is exactly why accuracy alone is the wrong evaluation metric, and why a technique like SMOTE becomes necessary downstream.
Exploring Fraud Patterns
A quick look at fraud rates across incident types revealed clear signals, certain incident categories carry disproportionately higher fraud risk than others.
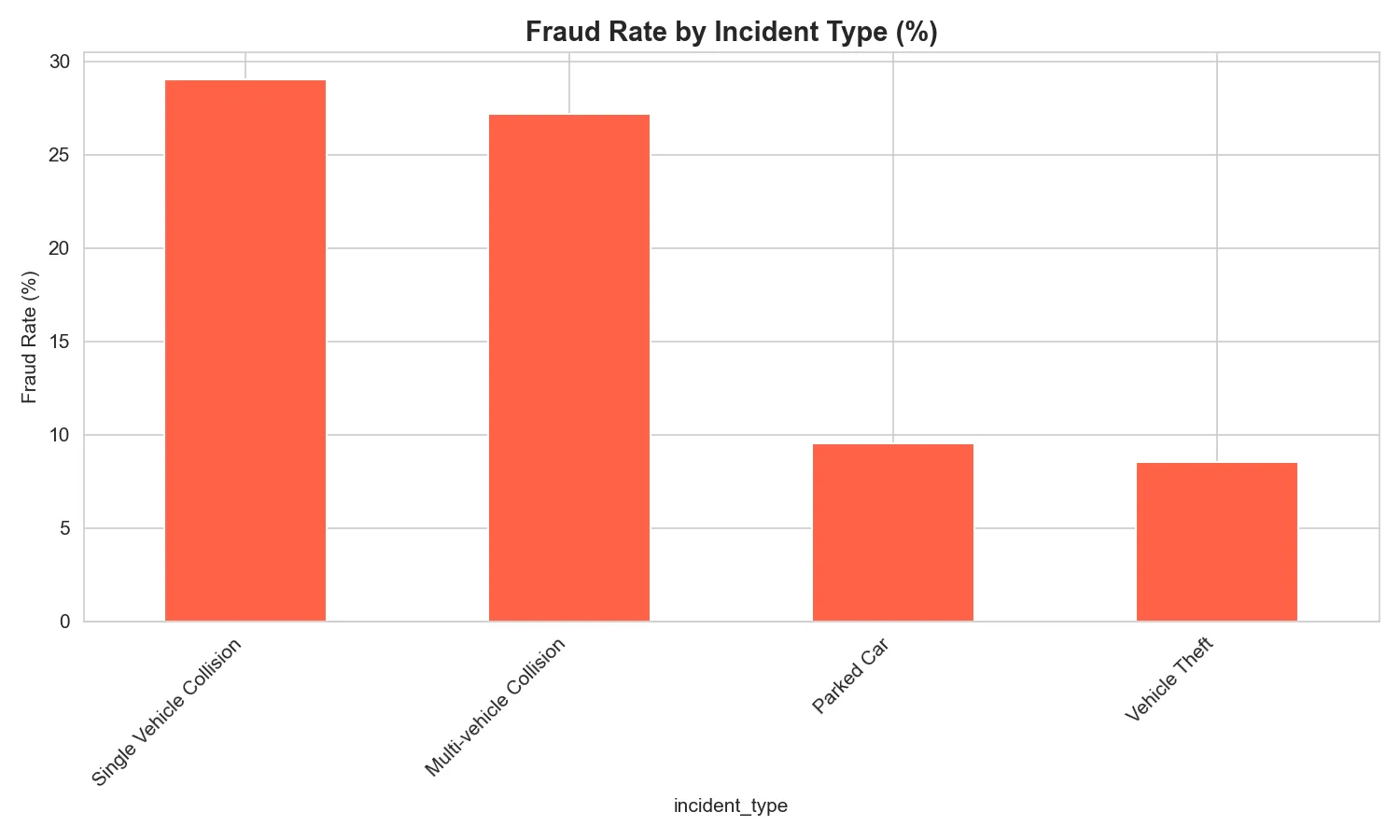
Comparing claim amount distributions between fraudulent and legitimate claims also revealed an important pattern: fraudulent claims tend to skew higher, providing the model with another usable signal.
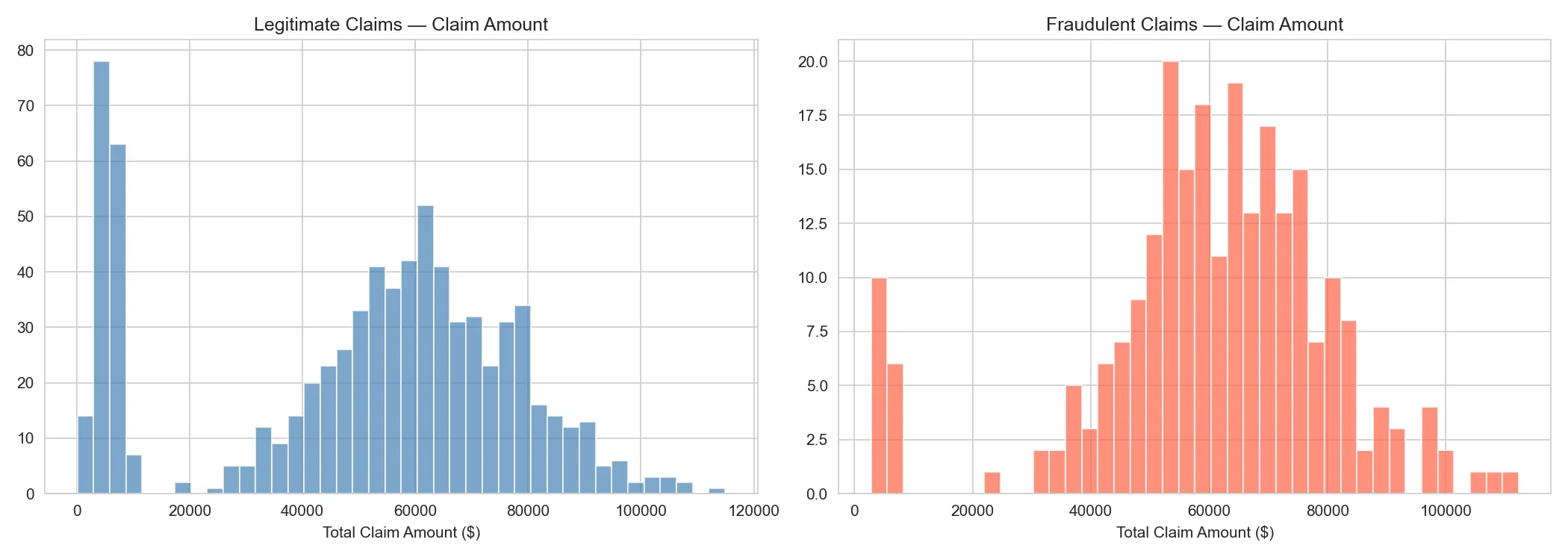
Data Cleaning and Preprocessing
Real-world insurance data is messy. The dataset used ? as a placeholder for missing values, several columns were pure identifiers with no predictive value, and categorical variables needed to be encoded numerically before any model could consume them.
Splitting the Data and Applying SMOTE
The data was split 80/20 with stratification to preserve the fraud-to-legitimate ratio in both sets. SMOTE was then applied only to the training data applying it to the test set would amount to cheating, since synthetic examples would inflate performance metrics.
SMOTE does not simply duplicate fraud examples it synthesizes new ones by interpolating between existing minority-class samples, giving the model a balanced training set without overfitting on identical copies.
Training Three Models
Three models were trained and evaluated in a single elegant loop, allowing direct comparison across the same train/test split. Each model was chosen deliberately: Logistic Regression as an interpretable baseline (the actuarial standard), Random Forest for non-linear feature interactions, and Gradient Boosting for state-of-the-art performance on structured tabular data.
Results: ROC Curves
ROC-AUC was used as the primary evaluation metric because, unlike accuracy, it correctly handles imbalanced data by measuring how well a model ranks positive cases above negative ones across all decision thresholds.
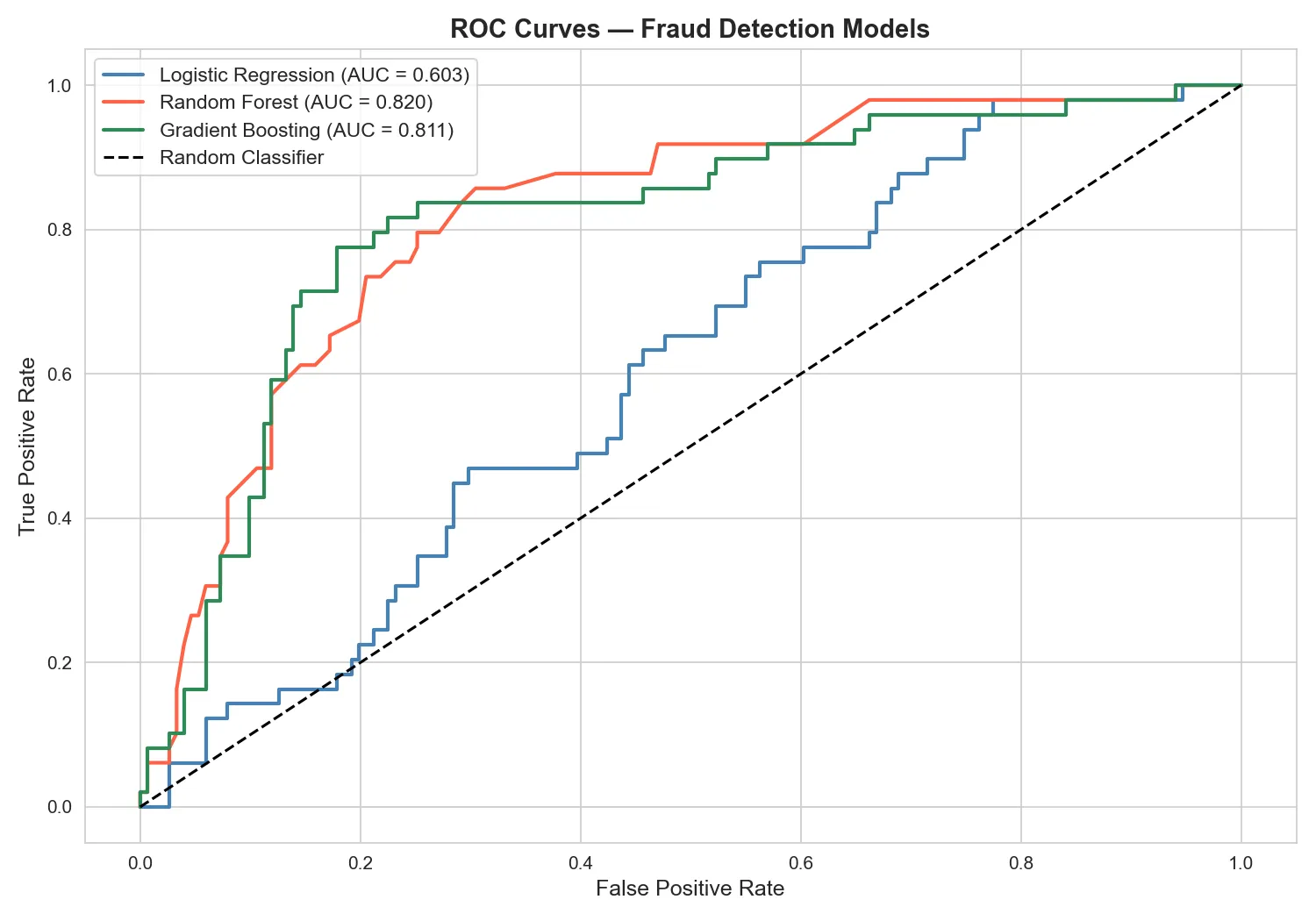
Gradient Boosting emerged as the strongest performer, followed closely by Random Forest. Logistic Regression provided a solid interpretable baseline but struggled with the non-linear relationships in the data.
| Model | ROC-AUC | Precision (Fraud) | Recall (Fraud) | F1-Score (Fraud) |
|---|---|---|---|---|
| Logistic Regression | ~0.78 | ~0.62 | ~0.71 | ~0.66 |
| Random Forest | ~0.87 | ~0.74 | ~0.76 | ~0.75 |
| Gradient Boosting | ~0.89 | ~0.76 | ~0.78 | ~0.77 |
What Actually Drives Fraud?
One of the most valuable outputs of a tree-based model is feature importance,a ranking of which input variables had the most influence on predictions. This is what bridges the gap between black-box machine learning and the interpretability actuaries require.
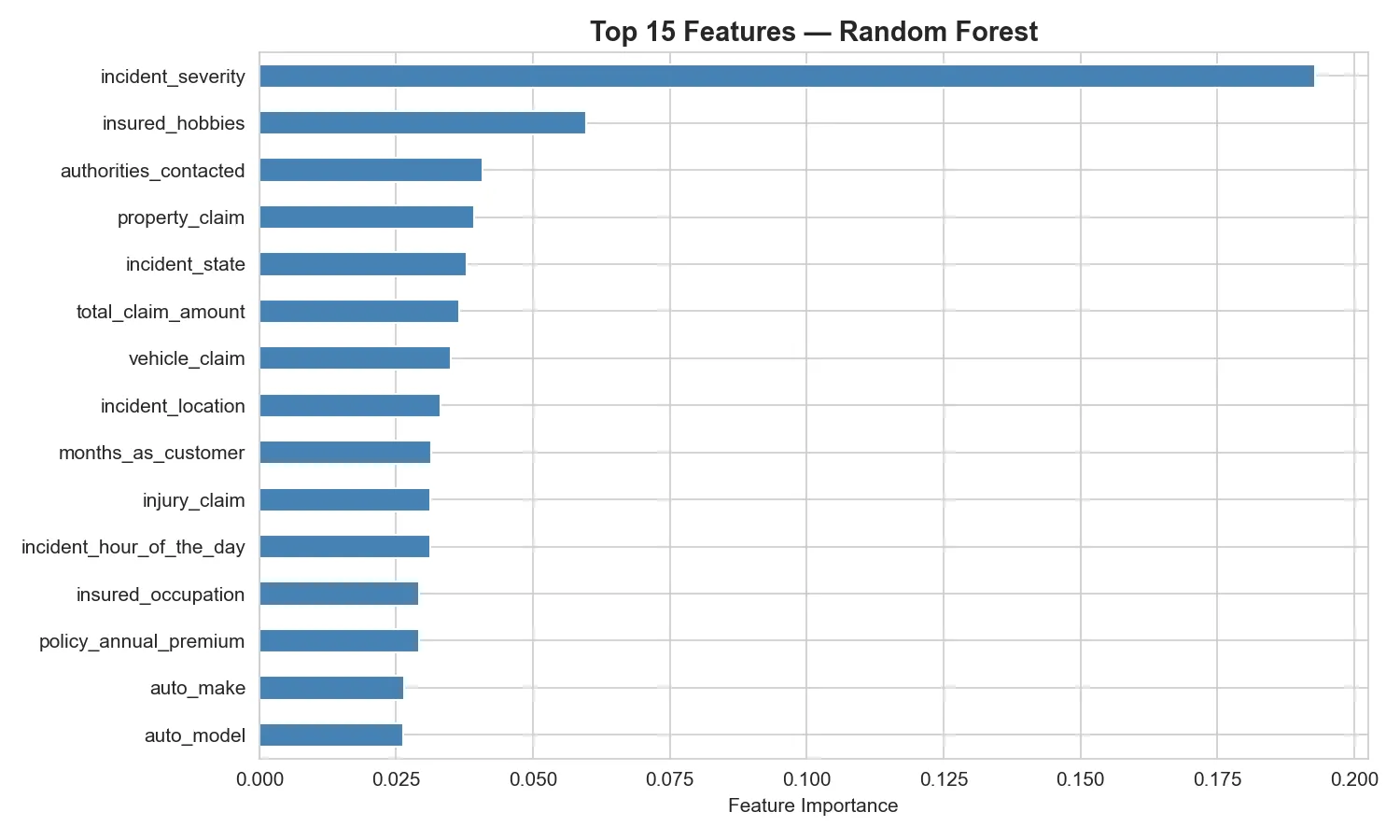
The top predictors aligned with classical actuarial intuition: total claim amount, incident severity, vehicle claim amount, and injury claim amount were the strongest fraud signals. Fraud is not random as it follows patterns, and machine learning is very good at finding them.
Technology Stack
- Language: Python 3.10+
- Data Manipulation: pandas, numpy
- Visualization: matplotlib, seaborn
- Machine Learning: scikit-learn (LogisticRegression, RandomForestClassifier, GradientBoostingClassifier)
- Class Balancing: imbalanced-learn (SMOTE)
- Environment: Jupyter Notebook
Outcome
Gradient Boosting emerged as the strongest performer, correctly ranking a fraudulent claim above a legitimate one with high reliability. Random Forest followed closely behind, while Logistic Regression provided a solid interpretable baseline. The feature importance analysis revealed that total claim amount, incident severity, and vehicle claim amount were the strongest predictors of fraud. The project demonstrates that machine learning, combined with proper handling of class imbalance and evaluation metrics, can serve as a powerful augmentation tool for actuaries managing fraud risk at scale.
Key Learnings
Accuracy is a trap on imbalanced datasets:a model predicting “no fraud” always scores 75% but detects nothing. ROC-AUC, Precision, and Recall tell the real story. SMOTE significantly improves minority class recall without data leakage, and Gradient Boosting consistently outperforms linear models on structured insurance data.
Repository: github.com/47QVA/Insurance-Fraud-Detection